这句话是1929年还在柏林的爱因斯坦接受塞缪尔·伍尔夫(Samuel J. Woolf)的采访时所说,最终发布在1929年8月29日纽约时报上[1]。
“If A is success in life,” he replied, “I should say the formula is A=X Y Z, X being work and Y being play.” “And what,” I asked, “is Z?”“That,” he answered, “is keeping your mouth shut.”
This experience gave me also an opportunity to learn a fact-a remarkable one, in my opinion: A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.
When you sit with a nice girl for two hours you think it’s only a minute, but when you sit on a hot stove for a minute you think it’s two hours. That’s relativity.
[1]1929 August 18, New York Times, Section 5: The New York Times Magazine, Einstein’s Own Corner of Space by S. J. Woolf, Start Page SM1, Quote Page SM2, Column 5, New York.
[2]1939, The Social Function of Science by J. D. Bernal (John Desmond Bernal), Quote Page 9, G. Routledge & Sons Ltd., London.
[3]New York Herald Tribune, September 12, 1933
[4]1964 [Copyright 1963], Inventing the future by Dennis Gabor, Page 207, Alfred A, Knopf, New York.
[5]Date: 1975 June 16, Periodical: Newsweek, Article: Alvin H. Hansen, 1887-1975, Author: Paul A. Samuelson, Quote Page 72, Publisher: Newsweek, Inc., New York.
[6]1968 (Copyright 1949), Scientific Autobiography and Other Papers by Max Planck (Max Karl Ernst Ludwig Planck), Translated from German by Frank Gaynor, Section: A Scientific Autobiography, Start Page 13, Quote Page 33 and 34, Greenwood Press Publishers, Westport, Connecticut.
[7]1929 March 15, New York Times, Einstein Is Found Hiding On Birthday: Busy With Gift Microscope, (Wireless to The New York Times), Quote Page 3, Column 3, New York. (ProQuest)
在论文「Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients」中,我们展示了如何将神经进化和梯度相结合,以提高循环神经网络和深度神经网络的进化能力。这种方法可以使上百层的深度神经网络成功进化,远远超过了以前的神经进化方法所展示的可能性。我们通过计算网络输出关于权重的梯度(即,和在传统深度学习中使用误差梯度不同)来实现这一点,使得在随机突变的校准过程中,对最敏感的变量(相比其他变量而言)进行更加精细的处理,从而解决大型网络中随机变量的一个主要问题。
我们的论文对 A Visual Guide to Evolution Strategies(参见「从遗传算法到 OpenAI 新方向:进化策略工作机制全解」)进行了补充和完善。这是由 OpenAI 团队首先提出的想法(https://blog.openai.com/evolution-strategies/),即 ES 的变型——神经进化——可以在深度强化学习任务中竞争性地优化深度神经网络。但是,迄今为止,这个结果有没有更广泛的应用仍然只是猜想。通过进一步创新 ES,我们通过一个综合研究「On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent」深入了解 ES 和 SGD 的关联,探索 ES 梯度近似实际上和在 MNIST 中通过 SGD 在每个 mini-batch 上计算的的最优梯度的联系有多紧密,以及这种近似如何导致了优越的性能。我们发现,如果提供足够的计算来改善梯度近似,ES 能在 MNIST 上实现 99% 的准确率,这暗示着 ES 何以愈发成为深度强化学习的有力竞争者——因为在并行计算增加时,还没有方法能获得完美的梯度信息。
ES 不只是传统的有限差分
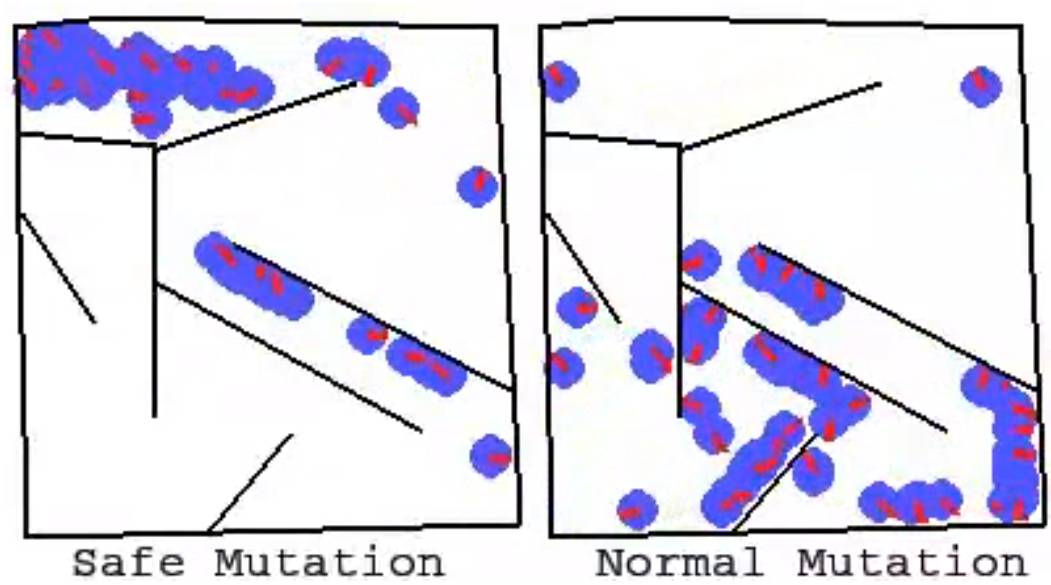
为了增加理解,一个伴随性研究「ES Is More Than Just a Traditional Finite-Difference Approximator」经验地证实,ES(具有足够大的扰动尺寸参数)的行为与 SGD 表现得有差别。这是因为 ES 优化的是一代策略群体(由概率分布描述,即搜索空间中的「云」)的预期回报,但 SGD 仅为单一的策略(搜索空间中的「点」)优化回报。这种变化使得 ES 可以访问搜索空间的不同区域,无论是好是坏(这两种情况都被示出)。对每代的参数扰动进行优化的另一个结果是,ES 获得了鲁棒性,这是 SGD 不能做到的。强调 ES 优化每代的参数这一做法,同样强调了 ES 和贝叶斯算法中的有趣联系。
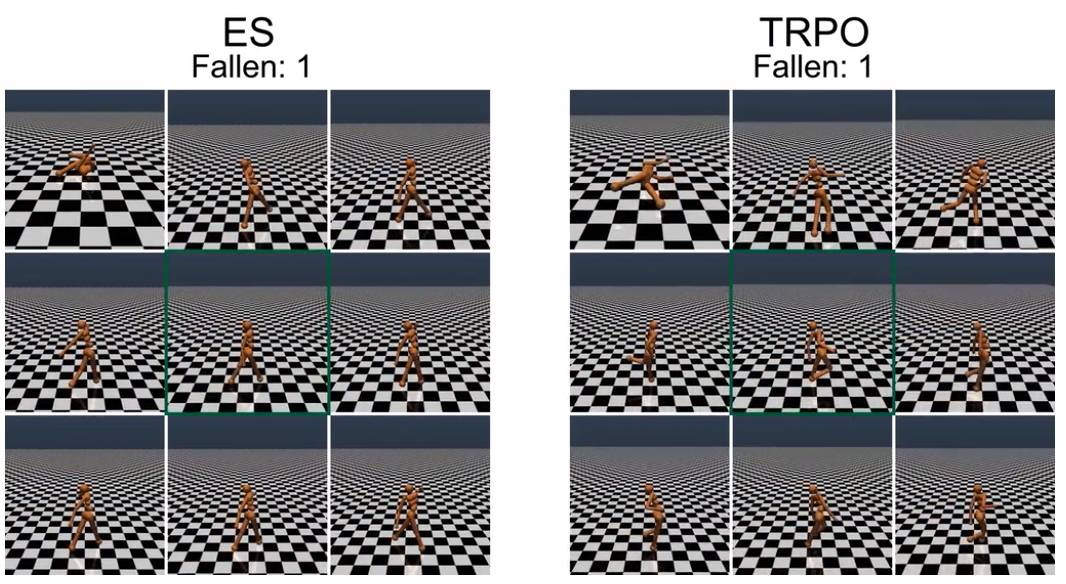
对步行者进行重量的随机扰动,TRPO 训练的步行者会产生明显的不稳定步态,而 ES 进化的步行者步态显得更加稳定。初始的训练步行者位于每个 9 帧合成的中心(绿框)。
传统的有限差分(梯度下降)不能跨越低适合度(fitness)的窄缝,但 ES 能容易地穿过并寻找另一侧的更高适合度。
ES 会在高适合度的窄缝中慢慢停止,但传统的有限差分(梯度下降)会毫无停顿地通过相同的路径。这与前面的动画一起说明了两种不同方法的区别和权衡。
加强对 ES 的探索
深度神经进化有一个令人兴奋的结果:之前为神经进化开发的工具集,现在成为了加强深度神经网络训练的候选者。我们通过引入新的算法「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」进行探索,这种算法将 ES 的优化能力和可扩展性与神经进化所独有的、通过群体激励将不同智能体区别开的促进强化学习领域的探索结合起来。这种基于群体的探索有别于强化学习中单一智能体传统,包括最近在深度强化学习领域的探究工作。我们的实验表明,通过增加这种新的探索方式,能够提高 ES 在许多需要探索的领域(包括一些 Atari 游戏和 Mujoco 模拟器中的类人动作任务)的性能,从而避免欺骗性的局部最优。
通过使用我们的超参数,ES 迅速收敛到局部最优,即不需要再次吸入氧气,因为吸入氧气暂时不能获得奖励。但是,通过探索,它学会了如何吸入氧气,从而在未来获得更高的奖励。请注意,Salimans et al. 2017 并没有报道 ES,根据他们的超参数,他们能够实现特定的局部最优。但是,就像我们所展示的,没有 ES,它很容易无限期地困在某些局部最优处(而那个探索能够帮助它跳出局部最优)。
「No-mini-batch ES」把针对 SGD 设计 mini-batch 传统替换为适用于 ES 的不同方法,从而改进梯度估计:这是这样一种算法,它在算法的每次迭代中,将整个训练批的一个随机子集分配给 ES 群体当中的每个成员。这种专用于 ES 的方法在等效计算的情况下提供了更好的准确度,且学习曲线甚至比 SGD 更加平滑。