中科院物理所
2017-12-21 09:56
不想用笔战斗的作家不是一个好士兵。
——鲁迅
从小到大经历了无数的语文考试,
在我们的笔下,
创造出了数不清的
像上面一样的『名人名言』。

作为一个致力于物理学前沿和科学传播的不正经公众号,今天我们就来盘点盘点,历史上的物理大咖们到底说过哪些让人印象深刻的话。
1
我们都知道爱因斯坦,一位才华横溢的科学家,我们不仅津津乐道简洁的质能方程,还有他关于相对论的深刻洞见。小编在小的时候,听说过爱因斯坦提出了一个成功的加法公式。
A=X Y Z
其中A就是成功,X就是努力工作,Y是懂得休息,Z是少说废话。
本来小的时候是深信不疑的,可在长大学了广义相对论,被折腾地死去活来以后,变得越发怀疑。这么简单的式子,当年爱因斯坦真的说过这句话么?是不是哪个人为了写自己的成功学书籍瞎编乱造的啊?
经过一番艰难的搜寻,小编我被事实啪啪啪地打脸。( ̄ε(# ̄)☆╰╮( ̄▽ ̄///)
这句话是1929年还在柏林的爱因斯坦接受塞缪尔·伍尔夫(Samuel J. Woolf)的采访时所说,最终发布在1929年8月29日纽约时报上[1]。
“If A is success in life,” he replied, “I should say the formula is A=X Y Z, X being work and Y being play.” “And what,” I asked, “is Z?”“That,” he answered, “is keeping your mouth shut.”
尽管这句话里面真的是浓浓的鸡汤味,但是毕竟是陈年的上好鸡汤,好汤,好喝。只有专心工作,劳逸结合,少说废话,才能做出优秀的科研成果。老爱的话,没毛病!

2
上古的物理大神们的名言,其实也不仅仅只是上好鸡汤,还有一些包含了对于他们对于物理这个学科深刻的理解以及对其他学科的不深刻的见地。
All science is either physics or stamp collecting.
这句话出自卢瑟福[2]。对,就是那个因为做了金箔实验,提出原子空间大都是空的,电子像行星围绕原子核旋转的卢瑟福模型的卢瑟福。不过现实总是充满了讽刺的意味。现在看起来最让人觉得有趣的在于,卢瑟福拿的诺贝尔奖不是诺贝尔物理奖,而是因为“对元素蜕变以及放射化学的研究”获得诺贝尔化学奖。对于这一点,他一直不是太开心,因为他自认为是一个物理学家,而不是一个化学家。
这位语不惊人死不休的大咖说的让人『印象深刻』的话不止这一句。

图片来自
http://izquotes.com/quote/350499
核反应产生的能量是很微弱的,你们要是想用这个方式来获取能量那简直是做梦[3]。不过现实是什么样,大家也都清楚。
3
当然,除了以上两个不太主流的名言流传了下来以外,还有一些充满了战天斗地的气息,看了就让人觉得血脉偾张的名言,比如
We cannot predict the future,
but we can invent it.
这句话来自Dennis Gabor写的《创造未来》(Inventing the future)这本书上。这位作者尽管名气不如前面两位如雷贯耳,但是也是一个物理大咖——因为对全息摄影的贡献,获得1971年诺贝尔物理学奖。

1947年肖克利、巴丁和布拉顿发明的点接触型的锗晶体管
目前AR,VR技术开始逐渐普及,虚拟现实放在现在已经不是一个玩笑话。但是放在十年前,二十年前,提出这个想法的人可能会更大概率地当成一个疯子。在1947年时刚发明点接触型的锗晶体管时,肖克利、巴丁和布拉顿大概怎么也不会想到70年后的今天,电子器件居然可以发展到这么便携,功能这么强大。科幻家们用想象力描绘未来光辉靓丽的景色,而对于物理学家而言,更多的时候是解决问题创造未来。
4
科学的发展从来不是一帆风顺,物理理论革新的过程更是科学家们的血泪史。著名经济学家保罗·萨缪尔森(Paul Anthony Samuelson)曾经引用普朗克的一段话[5]:
Science make progress funeral by funeral。
这句话是不是真实地出自普朗克本人,目前已经不得而知,在所能查找到的资料中,可以确信的是普朗克确实表达过类似的想法。[6]
This experience gave me also an opportunity to learn a fact-a remarkable one, in my opinion: A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.
一个新的科学真理不会通过说服对手看到光明从而取得胜利,而是因为它的反对者最终死亡,新的熟悉它的一代长大了才能成功。

学生时代的普朗克
对于提出量子论,不断在经典理论和量子理论中摇摆不定的普朗克而言,这句话大概是他的心声了。
5
在长长的历史中,除了上面所述的几种以外,还有一些关于前沿物理理论的俏皮解释也会被人们记住。爱因斯坦当年对于不断上门讨教相对论的人有点不厌其烦,交代他的秘书这么说:
When you sit with a nice girl for two hours you think it’s only a minute, but when you sit on a hot stove for a minute you think it’s two hours. That’s relativity.

“当你坐在好姑娘边上时,你会觉得度年如日;当你坐在滚烫的火炉上时,大概感觉度日如年。这就是相对论。”[7]
6
以后,大家不免还是继续写文章,除了逻辑清晰的论述与推理以外,引用名人故事和名人名言来充实内容也是一个不错的手段。以上介绍了的句子请大家放心使用,绝对没有添加不安全的材料。
为了点题,请让允许小编我用不是名言的句子作结实在没找到其他鸡汤素材

像质子一样思考,永远积极向上。positive同时有正电荷和积极向上之意。
2017年也快结束了,这句话就送给大家啦。
文中关于名人名言出处除了特殊标注外,均参考quoteinvestigator.com。具体来源见参考文献。
参考文献:
[1]1929 August 18, New York Times, Section 5: The New York Times Magazine, Einstein’s Own Corner of Space by S. J. Woolf, Start Page SM1, Quote Page SM2, Column 5, New York.
[2]1939, The Social Function of Science by J. D. Bernal (John Desmond Bernal), Quote Page 9, G. Routledge & Sons Ltd., London.
[3]New York Herald Tribune, September 12, 1933
[4]1964 [Copyright 1963], Inventing the future by Dennis Gabor, Page 207, Alfred A, Knopf, New York.
[5]Date: 1975 June 16, Periodical: Newsweek, Article: Alvin H. Hansen, 1887-1975, Author: Paul A. Samuelson, Quote Page 72, Publisher: Newsweek, Inc., New York.
[6]1968 (Copyright 1949), Scientific Autobiography and Other Papers by Max Planck (Max Karl Ernst Ludwig Planck), Translated from German by Frank Gaynor, Section: A Scientific Autobiography, Start Page 13, Quote Page 33 and 34, Greenwood Press Publishers, Westport, Connecticut.
[7]1929 March 15, New York Times, Einstein Is Found Hiding On Birthday: Busy With Gift Microscope, (Wireless to The New York Times), Quote Page 3, Column 3, New York. (ProQuest)
编辑:Cloudiiink
声明:本文由入驻搜狐号的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。
前沿 | 利用遗传算法优化神经网络:Uber提出深度学习训练新方式
机器之心
2017-12-22 13:18
选自Uber
作者:Kenneth O. Stanley、Jeff Clune
参与:陈韵竹、刘晓坤
在深度学习领域,对于具有上百万个连接的多层深度神经网络(DNN),现在往往通过随机梯度下降(SGD)算法进行常规训练。许多人认为,SGD 算法有效计算梯度的能力对于这种训练能力而言至关重要。但是,Uber 近日发布的五篇论文表明,神经进化(neuroevolution)这种利用遗传算法的神经网络优化策略,也是训练深度神经网络解决强化学习(RL)问题的有效方法。

Uber 涉及领域广泛,其中许多领域都可以利用机器学习改进其运作。开发包括神经进化在内的各种有力的学习方法将帮助 Uber 发展更安全、更可靠的运输方案。
遗传算法——训练深度学习网络的有力竞争者
我们惊讶地发现,通过使用我们发明的一种新技术来高效演化 DNN,一个极其简单的遗传算法(GA)可以训练含有超过 400 万参数的深度卷积网络,从而可以在像素级别上玩 Atari 游戏;而且,它能在许多游戏中比现代深度强化学习(RL)算法(例如 DQN 和 A3C)或进化策略(ES)表现得更好,同时由于更好的并行化能达到更快的速度。这个结果非常出乎意料:遗传算法并非基于梯度进行计算,没人能预料遗传算法能扩展到如此大的参数空间;而且,使用遗传算法却能与最先进的强化学习算法媲美、甚至超过强化学习,这在以前看来是根本不可能的。我们进一步表明,现代遗传算法的增强功能提高了遗传算法的能力,例如新颖性搜索(novelty research),它同样在 DNN 规模上发挥作用,且能够促进对于欺骗性问题(存在挑战性局部最优的问题)的探索。要知道,这些欺骗性问题通常对奖励最优化算法形成障碍,例如 Q 学习(DQN)、策略梯度算法(A3C)、进化策略(ES)以及遗传算法。
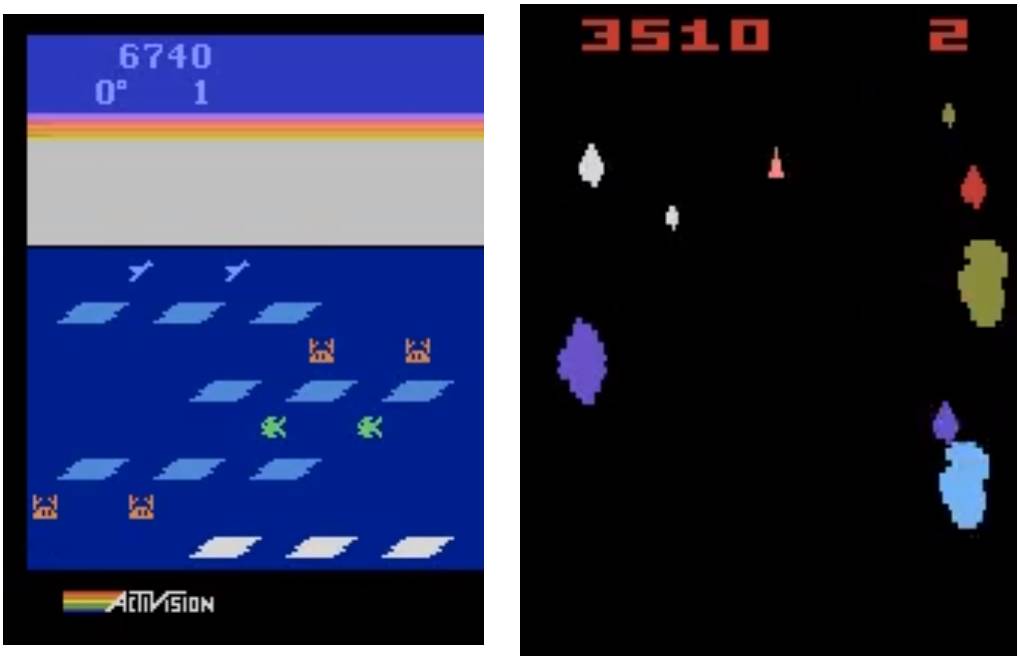
左:遗传算法在 Frostbite 中得分 10500。DQN、AC3 和 ES 的得分均未超过 1000;右:遗传算法在 Asteroids 也表现得很好。它的平均表现超越了 DQN 和 ES,但没有超过 A3C。
通过梯度计算的安全突变
在论文「Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients」中,我们展示了如何将神经进化和梯度相结合,以提高循环神经网络和深度神经网络的进化能力。这种方法可以使上百层的深度神经网络成功进化,远远超过了以前的神经进化方法所展示的可能性。我们通过计算网络输出关于权重的梯度(即,和在传统深度学习中使用误差梯度不同)来实现这一点,使得在随机突变的校准过程中,对最敏感的变量(相比其他变量而言)进行更加精细的处理,从而解决大型网络中随机变量的一个主要问题。
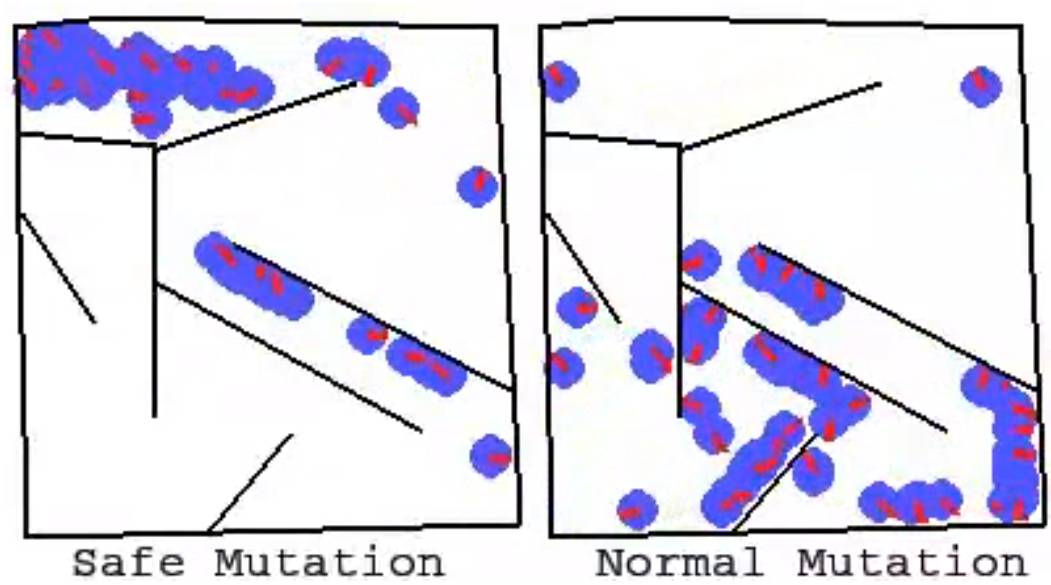
这两个动画展示了用于解决迷宫问题的单个网络的一批突变(左下角是起点,左上角是终点)。一般的突变大多不能解决这个问题,但是安全突变很大程度地在产生多样性的同时保留了解决问题的能力,表明了安全突变的显著优势。
ES 如何与 SGD 联系起来?
我们的论文对 A Visual Guide to Evolution Strategies(参见「从遗传算法到 OpenAI 新方向:进化策略工作机制全解」)进行了补充和完善。这是由 OpenAI 团队首先提出的想法(
https://blog.openai.com/evolution-strategies/),即 ES 的变型——神经进化——可以在深度强化学习任务中竞争性地优化深度神经网络。但是,迄今为止,这个结果有没有更广泛的应用仍然只是猜想。通过进一步创新 ES,我们通过一个综合研究「On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent」深入了解 ES 和 SGD 的关联,探索 ES 梯度近似实际上和在 MNIST 中通过 SGD 在每个 mini-batch 上计算的的最优梯度的联系有多紧密,以及这种近似如何导致了优越的性能。我们发现,如果提供足够的计算来改善梯度近似,ES 能在 MNIST 上实现 99% 的准确率,这暗示着 ES 何以愈发成为深度强化学习的有力竞争者——因为在并行计算增加时,还没有方法能获得完美的梯度信息。
ES 不只是传统的有限差分
为了增加理解,一个伴随性研究「ES Is More Than Just a Traditional Finite-Difference Approximator」经验地证实,ES(具有足够大的扰动尺寸参数)的行为与 SGD 表现得有差别。这是因为 ES 优化的是一代策略群体(由概率分布描述,即搜索空间中的「云」)的预期回报,但 SGD 仅为单一的策略(搜索空间中的「点」)优化回报。这种变化使得 ES 可以访问搜索空间的不同区域,无论是好是坏(这两种情况都被示出)。对每代的参数扰动进行优化的另一个结果是,ES 获得了鲁棒性,这是 SGD 不能做到的。强调 ES 优化每代的参数这一做法,同样强调了 ES 和贝叶斯算法中的有趣联系。
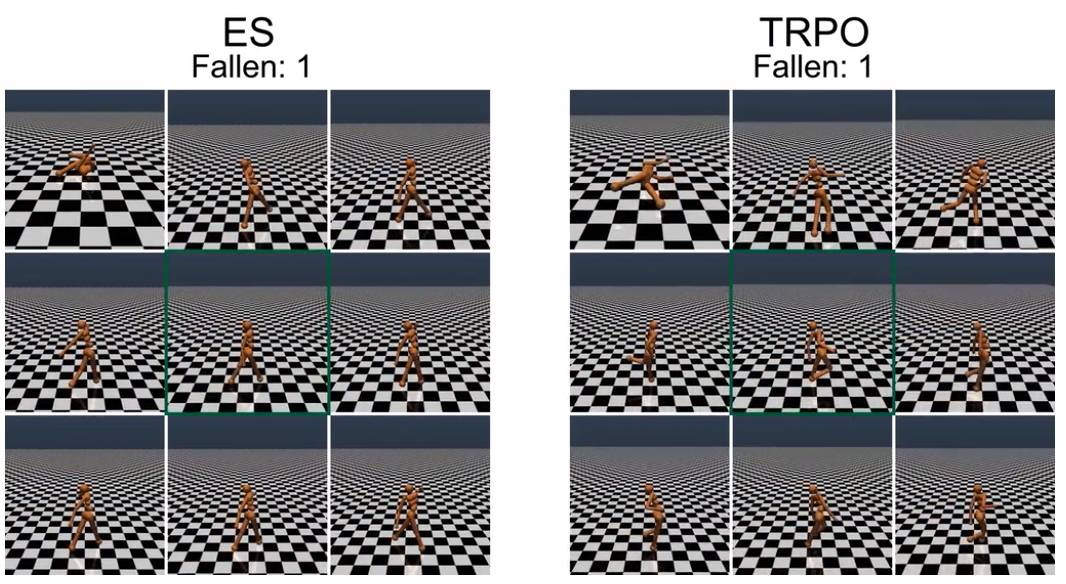
对步行者进行重量的随机扰动,TRPO 训练的步行者会产生明显的不稳定步态,而 ES 进化的步行者步态显得更加稳定。初始的训练步行者位于每个 9 帧合成的中心(绿框)。

传统的有限差分(梯度下降)不能跨越低适合度(fitness)的窄缝,但 ES 能容易地穿过并寻找另一侧的更高适合度。

ES 会在高适合度的窄缝中慢慢停止,但传统的有限差分(梯度下降)会毫无停顿地通过相同的路径。这与前面的动画一起说明了两种不同方法的区别和权衡。
加强对 ES 的探索
深度神经进化有一个令人兴奋的结果:之前为神经进化开发的工具集,现在成为了加强深度神经网络训练的候选者。我们通过引入新的算法「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」进行探索,这种算法将 ES 的优化能力和可扩展性与神经进化所独有的、通过群体激励将不同智能体区别开的促进强化学习领域的探索结合起来。这种基于群体的探索有别于强化学习中单一智能体传统,包括最近在深度强化学习领域的探究工作。我们的实验表明,通过增加这种新的探索方式,能够提高 ES 在许多需要探索的领域(包括一些 Atari 游戏和 Mujoco 模拟器中的类人动作任务)的性能,从而避免欺骗性的局部最优。

通过使用我们的超参数,ES 迅速收敛到局部最优,即不需要再次吸入氧气,因为吸入氧气暂时不能获得奖励。但是,通过探索,它学会了如何吸入氧气,从而在未来获得更高的奖励。请注意,Salimans et al. 2017 并没有报道 ES,根据他们的超参数,他们能够实现特定的局部最优。但是,就像我们所展示的,没有 ES,它很容易无限期地困在某些局部最优处(而那个探索能够帮助它跳出局部最优)。

智能体需要学着跑得尽可能远。ES 从未学过避免欺骗性的陷阱。但是,通过添加一个探索压力,其中一个学会了绕过陷阱。
结论
对有志于转向深度神经网络的神经进化研究人员,有几个重要因素值得考虑:首先,这种类型的实验需要的计算量比以前更多;对于这些新论文中的实验,我们经常需要运行成百上千个同步 CPU。但是,对 GPU 或 CPU 的需求不应该被视为一个负担;从长远来看,面对即将到来的世界,向大规模并行计算中心的规模变化也许意味着神经进化最能利用未来的优势。
新的结果与之前在低维神经进化中观察到的结果有显著差异。它们有效推翻了多年来的直觉,特别是对高维度探索的潜力的启发。正如在深度学习中发现的那样,在复杂性的某些阈值之上,在高维度的搜索似乎变得更加容易,因为它不易受到局部最优的影响。虽然深度学习已经对这种思维方式非常熟悉,但它的含义最近才在神经进化当中开始被理解。
神经进化的再度兴起,是旧算法与当代计算量相结合产生惊人成果的另一个例子。神经进化的可行性非常有趣,因为在神经进化社区中开发的许多技术可以立即在 DNN 规模上变得可行,它们每个都提供了不同工具以解决具有挑战性的问题。此外,正如我们的论文所展示的,神经进化搜索与 SGD 不同,因此为机器学习工具箱提供了有趣的替代方法。我们想知道,深度神经进化是否会像深度学习一样经历复兴。如果是这样,2017 年可能标志着这个时代的开始,我们也非常期待未来会发生什么!
下面是我们今天发布的 5 篇论文及关键发现的总结:
Deep Neuroevolution: Genetic Algorithms are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
用简单、传统、基于群体的遗传算法演化 DNN,在困难的深度强化学习问题上表现良好。在 Atari 游戏中,遗传算法表现良好,与 ES 以及基于 Q 学习(DQN)和政策梯度算法(A3C)的深度强化学习算法表现相当。
「深度遗传算法(Deep GA)」成功演化了有着 400 万自由参数的网络,这是通过一个传统的进化算法演化的最大的神经网络。
表明了一个有趣的事实:在某些情况下,根据梯度更新不是优化性能的最佳选择。
将 DNN 和新颖性搜索(Novelty Search)相结合,这种探索算法被设计用于欺骗性任务和稀疏奖励函数,以解决欺骗性的高维问题。其中,奖励最大化算法(例如 GA 和 ES)都在这类问题中失败了。
表明 Deep GA 的并行度优于 DQN、A3C 和 ES,因此运行比它们都快。可实现当前最先进的紧凑编码技术,只用几千字节就可以表示百万量级参数的 DNN。
包含在 Atari 中随机搜索的结果。令人惊讶的是,在一些游戏中,随机搜索大大优于 DQN、A3C 和 ES,不过它从没有超过 GA。
令人惊讶的是,在一个 DNN 中,随机搜索能比 DQN、A3C 和 ES 在 Frostbite 游戏中表现得更好,但是还是不能超过 GA。
Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
通过测量网络敏感性改变特定连接权重,基于梯度的安全突变(SM-G)极大提高了大型深度循环网络突变的效率。
计算关于权重的「输出」梯度,而非如常规深度学习中误差或损失函数的梯度,以允许随机但安全的搜索步骤。
这两种安全突变都不需要在领域当中的额外实验或展示。
结果:深层神经网络(超过 100 层)和大型循环网络现在只能通过 SM-G 的各种变形有效演化。
On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
通过比较不同情况下由 ES 计算的近似梯度和由 SGD 在 MNIST 中计算的准确梯度探究 ES 和 SGD 的关系。
开发快速代理,预测不同群体规模的 ES 预期表现。
介绍并演示不同加速和改善 ES 性能的方法。
有限扰动 ES(Limited perturbation ES)显著加快了在并行基础设施上的执行速度。
「No-mini-batch ES」把针对 SGD 设计 mini-batch 传统替换为适用于 ES 的不同方法,从而改进梯度估计:这是这样一种算法,它在算法的每次迭代中,将整个训练批的一个随机子集分配给 ES 群体当中的每个成员。这种专用于 ES 的方法在等效计算的情况下提供了更好的准确度,且学习曲线甚至比 SGD 更加平滑。
「No-mini-batch ES」在测试运行中达到了 99% 的准确率,这是在本次监督学习任务中,进化方法的最佳报告性能。
总体上有助于说明为什么 ES 能在强化学习中成为有力竞争者。通过搜索域的实验获得的梯度信息与监督学习的性能目标相比,信息量更少。
ES Is More Than Just a Traditional Finite Difference Approximator
强调 ES 和传统有限差分方法之间的重要区别,即 ES 优化的是最佳解决方案的分布函数(而非单个最佳的解决方案)。
一个有趣的结果:由 ES 发现的解决方案倾向于在参数扰动上保持鲁棒性。例如,我们表明 ES 的仿人类行走解决方案比 GA 和 TRPO 实现的类似解决方案对参数扰动的鲁棒性更强。
另一个重要结果:ES 可能可以解决传统方法困扰的一些问题,反之亦然。通过简单的例子说明 ES 和传统梯度跟随之间的不同动力学。
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
增加在 ES 中鼓励深度探索的能力。
表明通过探究不同代的智能体群体并用于促进小规模进化神经网络中的探索性算法——特别是新颖性搜索(NS)和质量多样性(QD)算法——能与 ES 结合,从而改善在稀疏或欺骗性深度强化学习任务当中的表现。
证实由此产生的新算法——NS-ES 和一个称为 NSR-ES 的 QD-ES 版本——能够避免 ES 所遭遇的局部最优问题,从而在某些任务中达到高性能。这些任务包括,模拟机器人学习绕过欺骗性陷阱达到高性能,以及 Atari 游戏当中的高维像素任务。
将这个基于群体的搜索算法系列添加到深度强化学习工具箱中。
原文链接:
https://eng.uber.com/deep-neuroevolution/
本文为机器之心编译,转载请联系本公众号获得授权。
声明:本文由入驻搜狐号的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。



